总结HotNets和HotMobile上感兴趣的文章。
HotNets'23涌现了一批大语言模型相关的文章,3篇都是Microsoft的,总结其中6篇如下:
Enhancing Network Management Using Code Generated by Large Language Models
Sathiya Kumaran Mani§ Yajie Zhou§† Kevin Hsieh§ Santiago Segarra§★ Trevor Eberl§ Eliran Azulai§ Ido Frizler§ Ranveer Chandra§ Srikanth Kandula§ [§Microsoft, †University of Maryland, ★Rice University]
本文主要介绍了如何利用大型语言模型(LLMs)生成网络管理任务的代码,允许网络运营商检查生成的代码以解决网络管理中的可解释性、可扩展性和隐私性挑战。文章提出了一个通用框架,利用LLMs生成特定任务的代码,以简化网络操作员的任务。作者还介绍了他们开发的基准测试NeMoEval,以及他们的实现和评估结果。
https://github.com/microsoft/NeMoEval
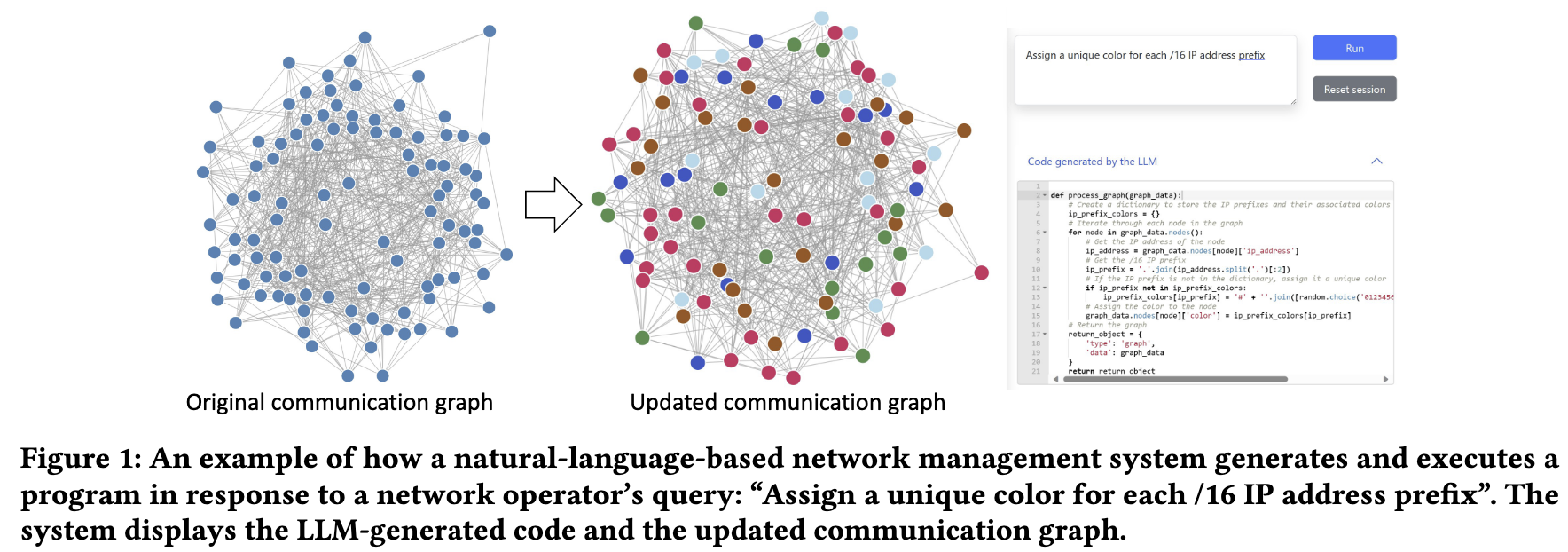
作者设计了一个名为 NeMoEval 的基准,用于评估基于大型语言模型(LLM)的网络管理系统。NeMoEval 包括三个主要组件:金牌答案选择器、结果评估器和结果记录器。
- Golden Answer Selector:对于每个输入用户查询,作者创建了一个包含预期正确代码功能的“金牌答案”,这些答案由人类专家验证。这些验证过的答案存储在选择器的字典文件中,作为评估 LLM 生成的代码的真实标准。
- Results Evaluator:系统在沙盒中执行 LLM 生成的代码,将结果(例如更新后的图或输出信息)与金牌答案的执行结果进行比较。
- Results Logger:为了分析 LLM 的性能和改进潜力,作者记录了每个查询的结果,包括 LLM 生成的代码、金牌答案和比较结果。还记录了任何代码执行错误。
LLMs在处理大规模网络拓扑和通信图时所面临的可解释性、可扩展性和隐私性挑战如何解决?
面临如下挑战:
- 可解释性:网络操作员需要理解LLM生成的代码是否正确地满足了查询需求,这对于评估LLM的方法和答案至关重要。
- 可扩展性:随着网络规模的增加,LLMs受到有限的令牌窗口大小的限制,这限制了它们处理大型网络拓扑和通信图的能力。Bard[20]、ChatGPT[44]和GPT-4[46]等现代llm在其提示中只允许2k到32k的令牌,这只能容纳具有数十个节点和数百个边的小型网络拓扑。
- 隐私性:网络数据可能包含个人身份信息(PII),如IP地址,这在将这些信息传输给LLM进行处理时引发了隐私问题。
解决方法:
- 可解释性:通过允许网络操作员查看LLM生成的代码,从而理解满足查询的底层逻辑。[依靠人工解决可解释性的问题]
- 可扩展性:通过移除与LLM共享网络数据的需要,从而克服了LLM处理大型网络拓扑和通信图时所面临的局限性。
- 隐私性:通过避免将包含个人身份信息(PII)的网络数据传输给LLM进行处理,从而解决了隐私问题。
LLMs在网络管理中的实际应用效果如何?
LLMs在网络管理中的实际应用效果表现良好,能够提高代码质量和网络管理效率。根据研究,使用LLMs生成的代码在网络流量分析和网络生命周期管理任务上的平均正确性分别达到了63%和56%(使用GPT-4模型分别达到了88%和78%),明显优于仅使用图数据输入到LLMs的基线方法(平均正确性为23%)。这表明使用LLMs生成的代码在网络管理任务中具有较高的可行性。
此外,通过采用互补程序合成方法(如pass@k和self-debug),可以进一步提高代码质量。在使用Bard模型和三个失败的网络生命周期查询的情况下,pass@k和self-debug方法分别提高了100%和67%的代码质量。这表明,应用互补技术具有很大潜力,可以进一步提高网络管理应用中LLM生成代码的准确性。
A Holistic View of AI-driven Network Incident Management
Pouya Hamadanian†, Behnaz Arzani§, Sadjad Fouladi§, Siva Kesava Reddy Kakarla§, Rodrigo Fonseca, Denizcan Billor∥ , Ahmad Cheema∥ , Edet Nkposong∥ , Ranveer Chandra§ [†MIT, §Microsoft Research, Azure Systems Research, ∥ Microsoft]
文章提出了一个整体框架来构建用于事件管理的 AI 助手,并讨论实现它所需的未来研究的几种途径。作者在设计此类助手时彻底分析了社区应该考虑的基本要求。文章基于与大型公共云提供商的运营商及其在事件管理中的先前经验的讨论,并尝试通过各种形式的自动化来改善事件管理体验。
设计用于事件管理的人工智能助手时需要考虑哪些基本要求?
- Iterative Prediction: 人工智能助手应该能够进行迭代预测,这意味着它应该能够根据新信息和反馈不断完善其预测。
- Reliable and Safe: 人工智能助手应在决策过程中优先考虑可靠性和安全性,确保其行为不会损害网络的稳定性或安全性。
- Adaptive: 人工智能助手应该适应网络组件、软件和硬件快速发展的性质。它应该能够适应不协调的变化,并有效地解决新的复杂事件。
大语言模型如何改善操作员的事件管理体验?
- Enhanced Root Cause Analysis: LLM可以通过处理和分析大量事件数据来增强实际的根本原因分析,使运营商能够更有效地识别网络事件的根本原因。
- Iterative Prediction: LLM可以促进迭代预测,允许运营商根据新信息和不断变化的事件模式不断完善其事件管理策略。
- Adaptive Incident Management: LLM可以适应网络组件快速演变的性质和不协调的变化,使运营商能够更有效地处理新的复杂事件。
- Automation Potential: LLM有可能使事件管理的某些方面自动化,例如识别模式,建议缓解策略,并根据历史事件数据提供见解。
LLM Agents的组成部分?
- Hypothesis Former: 这种LLM代理产生了bite-sized的假设,并在每个步骤中描述了可能的根本原因或缓解措施。它根据事件数据生成假设,并将其提交给operator批准,operator可以预先批准某些具有高置信度和低风险的建议。
- Hypothesis Tester: 此LLM代理将假设作为输入,并生成一个程序来验证它。它通过运行模拟或实验来测试假设,并向operator提供反馈。然后,operator可以根据结果批准或拒绝假设。
- Mitigation Planner: 此LLM代理根据批准的假设及其相应程序制定了详细的缓解计划。它生成一个step-by-step计划,供operator遵循,包括任何必要的配置更改或系统更新。然后,operator可以执行计划来缓解事件。
The Hypothesis Former generates hypotheses, the Hypothesis Tester verifies them, and the Mitigation Planner creates a detailed plan for the operator to execute.
What do LLMs need to Synthesize Correct Router Configurations?
Rajdeep Mondal, Alan Tang, Ryan Beckett, Todd Millstein, George Varghese [UCLA, Microsoft Research]
文章研究了大语言模型(例如,GPT4)是否可以合成正确的路由器配置以减少人工工作。文章发现GPT-4本身工作非常糟糕,其产生有希望的草案配置,但在拓扑,语法和语义方面存在严重错误。 文章提出Verified Prompt Programming,将GPT-4与验证器结合起来,并使用来自验证器的本地化反馈来自动纠正错误。验证需要规范和可操作的本地化反馈才能有效。 文章展示了两个用例的结果:在单个路由器上从Cisco转换到Juniper配置,以及在多个路由器上实现无传输策略。虽然仍然需要人工输入,但如果将leverage定义为自动提示的数量与人工提示的数量之比,实验显示,Juniper翻译的leverage为10倍,实现无传输策略的leverage为6倍,以经过验证的配置结束。
大语言模型如何合成路由器配置?为什么GPT-4表现不佳?
文章认为目前主要是pair programming,效率低,期望变成verified pair programming。
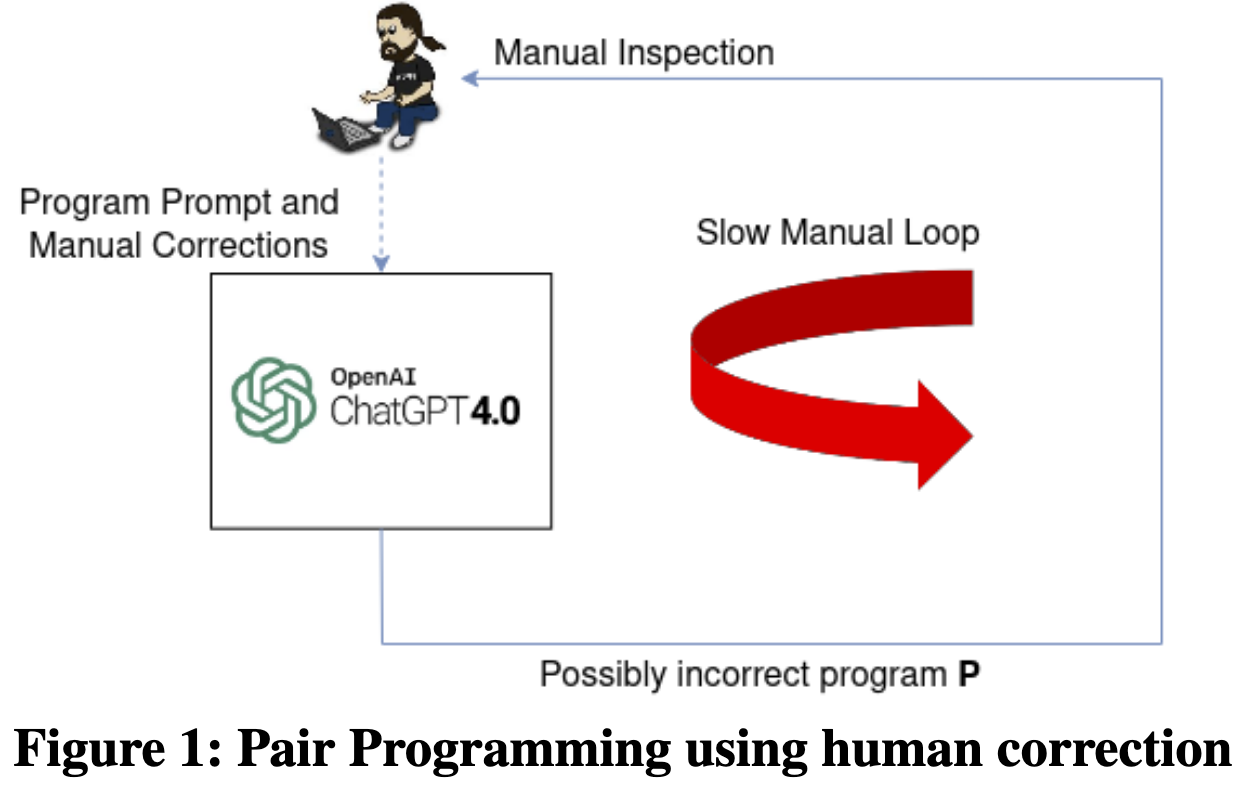
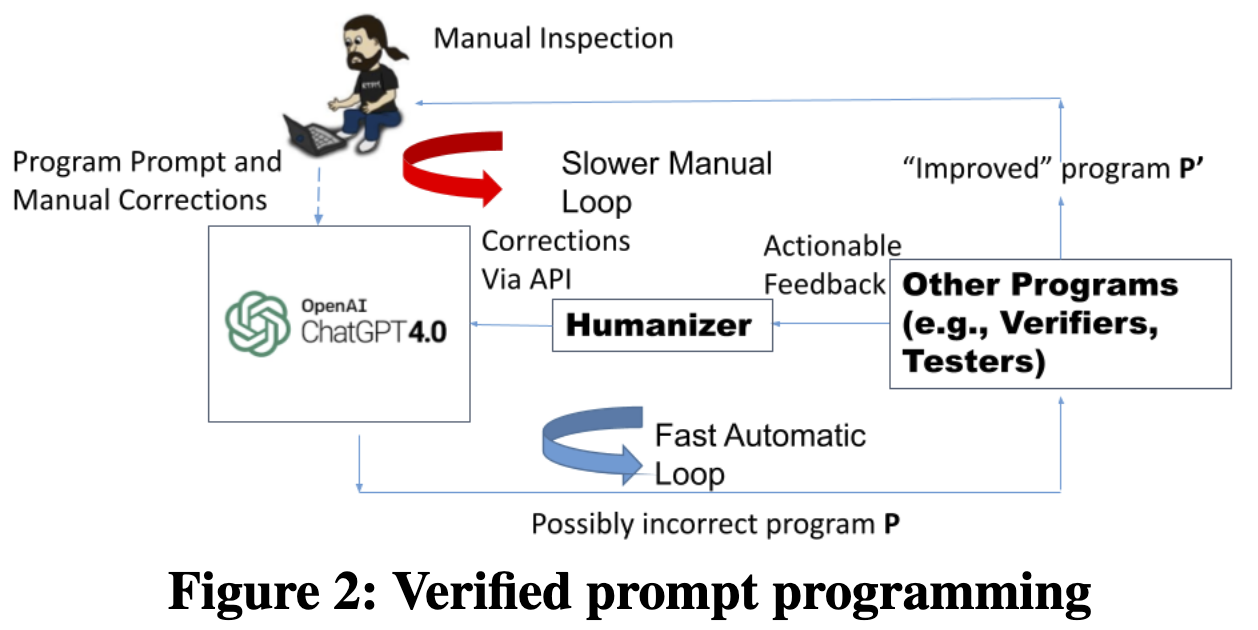
性能不佳的原因在于 GPT-4 无法理解路由器配置所需的深层语义和复杂细节。它更像是一个“白痴专家”,能够产生出色的输出,但也会犯简单的严重错误。
引入verifier的挑战?
- 验证者不能在没有规范的情况下证明正确性。在实践中,规范是不完整的,因此并非所有的解决方案实际上都是用户可以接受的。
- 为了让验证者自动(在最少的人工帮助下)与LLM交互,验证者必须提供可操作的反馈。文章发现LLM使用网络组件(单个路由器[11]甚至路由器内的路由图[12])的模块化验证反馈来纠正自己比使用整个网络更容易。
GPT-4和验证器如何结合?需要多少人工输入?
使用Verified Prompt Programming,该方法将 GPT-4 与验证器结合起来。 验证者提供本地化反馈,从而能够自动纠正错误。验证者的集成需要规范和可操作的本地化反馈以确保有效性。虽然人工输入仍然是必要的,但该方法显着减少了所涉及的人工工作量。例如,在一项实验中,Juniper 转换的杠杆率为 10 倍,实施无中转策略的杠杆率为 6 倍。
优化后的模型在生成正确的路由器配置方面表现如何?
该系统实现了更高的杠杆率,这意味着与自动提示的数量相比,需要更少的人工提示。该模型在更简单的用例中显示出合理的有效性,并且模块化验证对于向LLM提供可操作的反馈至关重要。然而,复杂的用例仍然需要进一步的测试和人工干预,因为模型有时会遇到复杂的细节和全局规范。
Toward Reproducing Network Research Results Using Large Language Models
Qiao Xiang∗, Yuling Lin∗, Mingjun Fang∗, Bang Huang∗, Siyong Huang∗, Ridi Wen∗, Franck Le†, Linghe Kong♦, Jiwu Shu∗◦ [∗Xiamen University, †IBM Research, ♦ Shanghai Jiao Tong University, ◦Minjiang University]
本文主要讨论了利用大型语言模型(LLM)来实现网络研究结果的复现。再现研究结果对网络社区很重要,当前的最佳实践通常采用:(1)寻找公开可用的原型; (2) 联系作者以获得私有原型; (3) 根据出版物的描述手动实施原型。然而,大多数已发表的网络研究没有公共原型,私人研究很难获得。因此,大多数重现的努力都花在基于出版物的手动实现上,这既费时又容易出错。 本文首先通过小规模实验证明了它的可行性,四个具有基本网络知识的学生通过prompt engineering ChatGPT 重现在突出会议和期刊上发布的不同网络系统。 文章接着提出了改进网络研究复现效率的方法,并讨论了处理网络研究中缺失细节和漏洞的策略。最后,文章还提出了构建针对网络研究复现的领域特定LLM的想法。
如何利用大型语言模型来实现网络研究结果的复现?
- 选择适当的网络系统:选择合适的网络系统进行复现,确保它们是软件系统,可以用通用编程语言(如Java和Python)实现,并且在中心化控制器中运行。
- 构建模块化提示:为系统的不同组件提供分离的、模块化的提示,而不是一次性为整个系统提供单一的、庞大的提示。这有助于更成功地复现系统。
- 使用伪代码:首先使用伪代码来实现系统的组件,因为伪代码是离实际代码最近的部分。这样可以稳定地设置关键数据类型和结构,避免在实现其他组件时更改它们。
- 数据预处理:确保在系统复现过程中进行有效的数据预处理,因为研究论文通常没有提供数据预处理的详细信息。
- 调试:在调试过程中,发送错误消息、错误测试用例和详细的提示以解决数据类型错误、逻辑错误等问题。
- 设计半自动或自动提示工程框架:为了提高复现过程的效率,可以设计一个半自动或自动提示工程框架。这个框架可以自动生成各个组件的多模态提示(例如逻辑谓词、伪代码、示例和测试用例),以生成和测试每个组件的代码。
文章总结了哪些经验教训?
- Asking LLMs to implement a system component by component, not the whole system all at once. 开始,所有参与者都试图发送 ChatGPT 提示,例如“实现 XX,其工作原理如下步骤 XXX”。ChatGPT 不能很好地响应这种单片提示。将系统划分为组件,对于每个组件,按顺序发送 ChatGPT 更详细的模块化提示以实现、调试和测试。这允许他们成功地重现系统。这表明 ChatGPT 理解系统设计和实现它的能力仍然仅限于小型系统和组件。
- Implementing components with pseudocode first. 假设首先要求 ChatGPT 在不生成伪代码的情况下实现组件,当稍后要求它使用伪代码实现组件时,生成的代码通常需要对先前生成的代码中的数据类型和结构进行实质性更改。这是因为 ChatGPT 实现了基于文本的提示所描述的组件,不同于基于伪代码的提示所描述的组件,从而导致互操作性问题。两名学生发现,使用伪代码实现组件允许 ChatGPT 稳定关键数据类型和结构,并在实施其他组件时避免更改它们。
- Data preprocessing is important to the system, but not to the research paper.
文章总结了哪些开放性问题?
-
处理已发布网络研究文章的多样性:这种多样性来自两方面:一是网络研究论文内容和细节的多样性;二是网络领域的多个主题(例如网络架构、可编程硬件和分布式系统)。为了解决这个问题,作者提议设计一个统一的提示工程框架,以便更有效地重现网络研究结果。
-
发现网络研究结果中的创新机会:通过使用大型语言模型辅助重现网络研究结果,可以帮助研究者更深入地理解已发表的研究成果,从而揭示创新机会。此外,这种方法还可以改进领域顶级会议的同行评审过程。
-
提高重现效率:为了提高使用大型语言模型重现网络研究结果的效率,作者计划自动化提示工程过程。作者的初步设计包括使用一个自然语言大型语言模型(例如ChatPDF)理解论文并提取其架构、关键组件和工作流程,然后将提取的信息转换为多模态提示(例如逻辑谓词、伪代码、示例和测试用例),以便为整个架构和每个组件生成代码。
-
处理已发布网络研究中的缺失细节和漏洞:由于时间和空间限制,作者可能在发布的研究中省略了一些非关键技术细节,这为重现这些结果带来了额外的挑战。为了处理这些问题,作者建议鼓励作者在校对过程中更仔细,并提供关于非关键细节和超参数的附录。另一种方法是以更好的结构格式(例如RFC或系统手册)撰写论文。
-
开发领域特定的大型语言模型以进行网络研究结果重现:这种领域特定的大型语言模型可以显著提高LLM辅助网络研究结果重现的范围和效率。早期证据支持这种方法的可行性,例如近期编程导向的大型语言模型在提供代码完成建议、识别和修复错误以及重现RFC方面取得的成功。
-
使用大型语言模型推动计算机网络教育和研究:通过与大型语言模型互动,学生可以获得在计算机网络和人工智能方面的职业技能。此外,这个过程有助于学生发现网络研究中的创新机会,从而提高同行评审过程的质量。
PROSPER: Extracting Protocol Specifications Using Large Language Models
Prakhar Sharma, Vinod Yegneswaran [SRI International]
本文主要介绍了一种名为PROSPER的框架,利用大型语言模型(LLMs)从RFC(请求评论)文档中自动理解和提取协议规范。文章首先介绍了RFC的复杂性和文本中存在的局限性,然后详细描述了PROSPER框架的构建和应用,包括代表性RFC的选择、工程化提示过程、文本和非自然语言文本图的提取等。最后,文章还提出了未来工作的方向,包括将PROSPER框架扩展到端到端自动化和将提取的输出应用于多个下游任务。
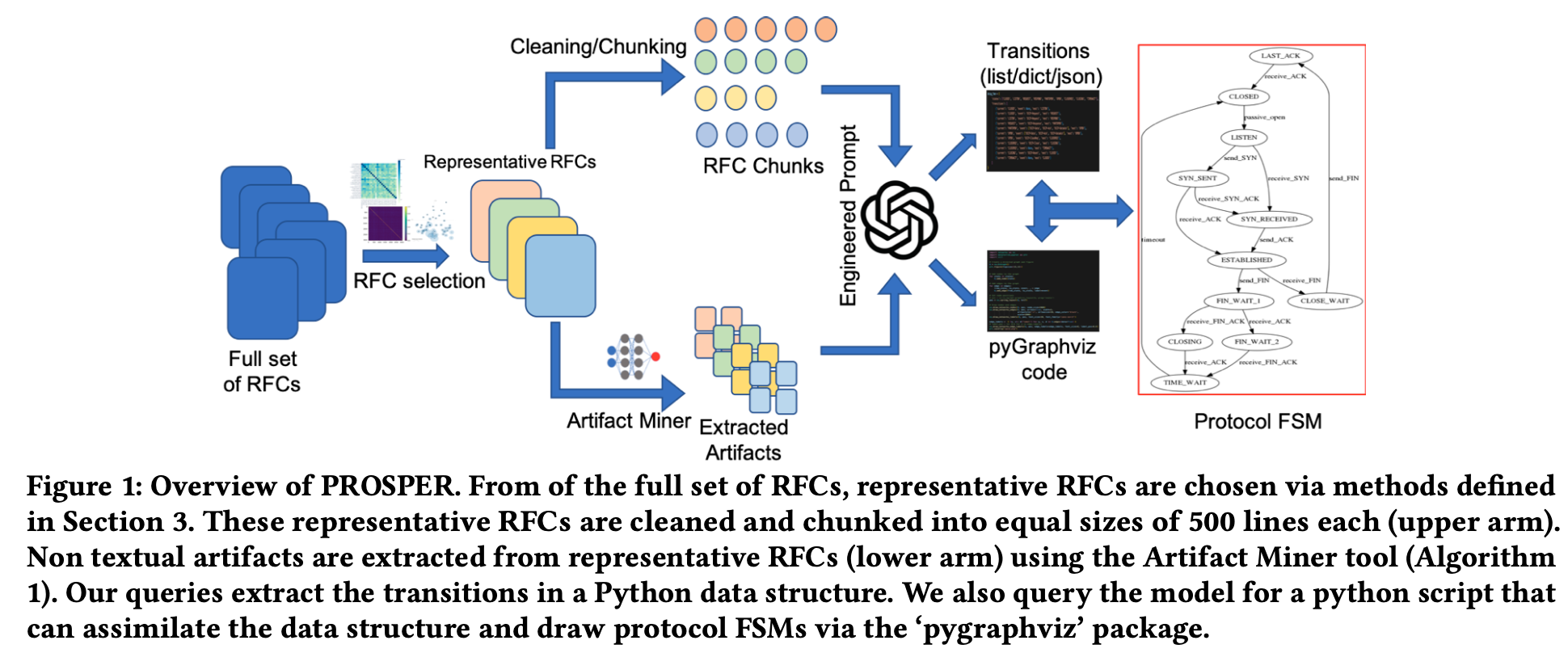
在自动理解RFC文档中存在的挑战有哪些?PROSPER框架是如何应对这些挑战的?
在自动理解RFC文档中存在的挑战主要包括以下几点:
- RFC文档的结构和设计不严格统一,因此自动提取信息的过程相当具有挑战性。RFC 包含自然文本中的协议定义,这些定义本质上是模棱两可的。
- 规范有限状态机(FSM)的定义不仅基于RFC中包含的信息,还基于领域专家的输入。
- 基于深度学习的信息提取和语义分割[14]在wikitableQuestions[19]等基准数据集上显示出了一些有前景的结果,但需要高质量且数量庞大的标注数据。在处理网络协议等技术领域时,生成高质量的标注数据是一项困难且昂贵的任务。
- RFC 中的规范 FSM 元素在文本中没有被详尽地覆盖。RFC 的一个关键元素是文本图,它是数据流过程、连接过程、消息结构、包头、变量定义等关键协议元素的图形描述,并且通常包含文本中没有明确提及的信息。
PROSPER框架通过以下方式应对这些挑战:
- 从RFC中提取有价值的协议信息,包括自动提取有限状态机(FSM)以及理解RFC中定义的控制消息的结构。
- 使用大型语言模型(LLM)从RFC中提取协议规范,因为预训练的LLM可以广泛泛化到大多数RFC。
- 开发一个名为Artifact Miner的工具,用于从RFC中提取非自然语言文本图形,这些图形通常包含关于协议的重要信息。
- 使用工程促销和评估相结合的方法,以提高模型从RFC中提取信息的能力。
大语言模型如何从RFC文档中提取协议规范?这种方法是否准确和高效?
- 使用 TF-IDF、Unionfind 和 BERTopic 算法以及来自领域专家的输入来选择具有代表性的 RFC文档,以便用于模型训练和评估(两部分)。
- 清理RFC,去除不相关的内容,如作者信息、页数、发布年份等。
- 将清理后的RFC分割成500行的块。
- 使用Artifact Miner工具提取RFC中的非自然语言文本图形。
- 利用工程化的提示,结合文本和提取的图形,从RFC中提取状态、过渡和事件。
We start with a seed prompt, which is a naively designed prompt that has the task description but is not optimized. These seed prompts are improved using the RFCs from the train set. We follow two broad strategies for prompt engineering: strategy 1: manual (greedy) and strategy 2: automatic prompt engineering, inspired by APE [30]. For strategy 1, we used the DCCP and TCP as train RFCs for prompt engineering. For strategy 2, we used DCCP and BGP as train RFCs.

关于准确性和高效性,PROSPER方法在DCCP RFC的FSM提取任务上,相较于现有方法实现了1.3倍的真阳性和6.5倍的假阳性减少。然而,在某些情况下,模型可能产生错误的过渡(假阳性),这可能是由于RFC中的信息缺失或模糊。使用大型语言模型从RFC文档中提取协议规范的方法在很大程度上是准确和高效的,但在某些情况下可能会出现错误。
存在哪些不足?
基础的NLP模型面临的一些问题:
- hallucinations (manifested as false positives in extraction)
- bias (the model sometimes reports states from a different RFC than the text it was provided)
- contextual misunderstanding (the model confuses message structures with FSM states in case of PPTP extraction).
PROSPER面临的其他问题:
- 返回格式确定性:由于大型语言模型(LLMs)是概率模型,正确的输出可能具有多种格式。为了避免这个问题,PROSPER 通过将 LLM 的输出以自回归方式反馈给自身,生成 'pyGraphviz' 代码。
- 端到端提取:与现有方法相比,PROSPER 在提取信息端到端方面做了权衡,以实现更好的通用性。作者正在努力改进方法,以移除人工介入,实现通用协议理解。
实现这一点的一种方法是使用最近发布的 LLM [3],它可以接受大上下文长度的输入,这将使分块变得不必要。GPT3.5-turbo 的上下文长度为 2048 个标记。来自我们代表性集的 RFC 的平均令牌数约为 48K。
- 缺乏定制基准数据集:目前没有针对 RFC 特定领域的标准化数据集。因此,评估输出的准确性和覆盖范围主要依赖人工。PROSPER 准备了一个类似 APE 的小型数据集用于提示的前向生成,但可以进一步改进。
Towards Integrating Formal Methods into ML-Based Systems for Networking
Fengchen Gong, Divya Raghunathan, Aarti Gupta, Maria Apostolaki [Princeton University]
由于其适应性和可扩展性,机器学习(ML)在网络社区中获得了显著的发展势头。然而,ML模型仍然可以产生与知识相矛盾的输出,即已建立的网络规则和原则。另一方面,形式方法(FM)使用基于知识的严格数学推理,但缺乏可扩展性。 为了充分利用这两种方法的互补优势,文章提倡将基于知识的FM集成到基于ML的网络问题系统中。通过队列长度预测案例,文章展示了单独使用ML模型或FM的好处和局限性。文章发现,在ML模型的训练和推理中加入FM不仅产生更可靠的结果,而且在各种下游任务中也有更好的性能。作者希望论文能够激发基于FM和基于ML的网络方法的更紧密集成,促进更健壮和可靠系统的开发。
在网络中集成基于 FM 和 ML 面临的挑战和限制?
- Incorporating Domain Knowledge:没有标准方法可以将领域知识引入到 ML 模型中,并且合并知识会显着增加学习过程的复杂性,这可能会导致复杂模型的可扩展性问题。
- Representing Accumulative Knowledge:以机器学习友好的方式表示数十年在网络微积分、网络层析成像和优化方面积累的知识是一项具有挑战性的任务。
- Scarcity or Bias of Datasets:利用知识来应对数据集的稀缺性或偏差是另一个需要解决的挑战。
- Verification of Learned Networking Principles:验证 ML 系统是否确实学习到了网络规则也很重要。
- Scalability of FM:基于 FM 的网络解决方案在扩展和学习模式方面存在困难。
如何将FM纳入到基于ML的系统中?
- 选择约束:从纯粹基于 ML 的方法开始,战略性地将 FM 模型的一些约束纳入其训练和推理中。
- 约束评估:选择可以直接在transformer输出上评估的约束,以保持系统可扩展性。
- 转换为可微分形式:将这些约束转换为可微分形式,以便将它们合并到transformer的损失函数中。
- 插补后校正:对于transformer未能满足的约束,利用Post-Imputation Correction调整以使输出满足约束。
将 FM 纳入 ML 模型的训练和推理中如何提高其可靠性和性能?
- 保证合理的结果:FM 允许表达有关系统如何运行的知识,并使用自动推理来查找符合观察到的测量的场景。这保证了结果是合理的,并且在给定观察到的测量和特定领域约束的情况下可能在系统中发生。
- 可扩展性和泛化性:将 FM 集成到基于 ML 的系统中可以产生具有健全性保证的更可靠的模型,可以用更少的数据进行训练并更好地泛化。
- 提高监控粒度:通过将 ML 与 FM 相结合,本文展示了与单独 ML 相比,队列长度监控粒度提高了 50 倍,结果提高了 11-96%。
- 解决具有挑战性的任务:细粒度的队列监控对于异常检测和配置等多个下游任务至关重要,通过将 FM 合并到基于 ML 的系统中可以显着改进。
有哪些网络问题可以从the integration of FM into ML-based systems中受益?
- Performance Estimators:基于 ML 的性能估计器(例如 DeepQueueNet 或 Mimicnet)可以通过根据共享缓冲区大小限制延迟预测来从 FM 中受益。
- Adversarial Examples for Network Protocols:生成网络协议的对抗性示例可以利用基于 ML 的解决方案来发现对抗性输入,利用基于 FM 的系统确保这些输入反映现实世界场景。
- Generating Synthetic Traces:在生成合成轨迹时,可以使用规则形式的知识将现有或合成轨迹转换为新轨迹,这可以从 FM 和 ML 的结合中受益。
Don't Forget the User: It's Time to Rethink Network Measurements
Aryan Taneja, Rahul Bothra, Debopam Bhattacherjee, Rohan Gandhi, Venkata N. Padmanabhan, Ranjita Bhagwan, Nagarajan Natarajan, Saikat Guha, Ross Cutler [Microsoft Research India, UIUC, Microsoft]
本文的主要内容是关于重新思考网络测量的重要性,强调了用户的角色以及利用用户的反馈来改进网络测量的方法。文章首先介绍了利用社交媒体上的用户情感来测量网络对应用性能和用户体验的影响,并列举了一些测量方法和先前的研究成果。接着讨论了网络测量的局限性,包括测量覆盖范围有限、需要专门的设备和资源等问题。然后,文章提出了使用非侵入性策略来量化网络性能对用户参与度的影响,并找出用户行为和明确反馈之间的相关性。最后,文章探讨了网络测量的目标和限制,并介绍了一些未来的研究方向。
如何利用用户的社交媒体情感来测量网络对应用性能和用户体验的影响?
- 分析用户在大规模视频会议服务(如MS Teams)中的隐式反馈,通过观察用户行为(如在会议中的出席率、摄像头开启情况等)来了解网络性能对用户体验的影响。
- 收集与SpaceX Starlink低地球轨道(LEO)卫星网络相关的社交媒体帖子,以捕捉用户对网络性能的显式反馈。通过分析这些帖子中的情感和观点,可以了解用户对网络性能的感知和满意度。
- 结合用户行为和社交媒体反馈,以更全面地了解网络性能对应用性能和用户体验的影响。这种方法不仅可以补充传统的网络测量技术,还可以为网络和网络服务提供商提供有关用户体验的有价值见解。
在网络测量中存在的局限性有哪些,如何解决这些问题?
网络测量中存在的局限性主要有以下两点:
- 传统的网络测量方法主要关注低级指标(如网络延迟和吞吐量),而这种方法虽然客观且富有洞察力,但缺乏对用户体验的全面了解。
- 网络测量的覆盖范围通常有限,因为执行这些测量通常需要在目标网络中有一个点的存在,而这可能超出普通研究者的范围。
解决这些问题的方法:
- 关注用户体验:通过利用用户的丰富反馈(隐式和显式)生成有关网络和网络服务的有用见解,从而改善网络测量方法。
- 利用社交媒体数据:分析用户在社交媒体上的评论和反馈,以更全面地了解网络性能和用户体验。
- 考虑不同平台和操作系统的影响:不同的平台(PC/移动设备,操作系统等)对用户对网络性能的敏感度有不同的影响,因此在网络测量中需要考虑这些差异。
- 使用用户参与度作为指标:用户参与度(如在线会议中的出席率、打开摄像头和麦克风的时间等)与用户体验密切相关,可以作为网络测量的替代指标。
- 使用用户信号作为服务(USaaS):通过收集和分析在线和离线的用户反馈,USaaS可以与现有的网络测量技术相辅相成,为网络和网络服务提供更全面的用户体验洞察。
如何使用非侵入性策略来量化网络性能对用户参与度的影响,并找出用户行为和明确反馈之间的相关性?
- 收集用户行为数据:
- 通过应用程序内部日志收集用户参与度指标,例如在线时间、打开摄像头/麦克风的时间等;
- 收集网络性能指标,例如延迟、丢包率、抖动和带宽;
- 分析网络性能与用户行为之间的关系:
- 对于每个网络性能指标,分析其与用户参与度指标之间的关系;
- 计算相关性,以确定网络性能指标对用户参与度的影响程度;
- 收集用户明确反馈:
- 通过问卷调查收集用户对服务质量的评分;
- 从社交媒体平台收集有关网络性能的用户评论;
- 分析用户行为与明确反馈之间的相关性:
- 计算用户参与度指标与服务质量评分之间的相关性;
- 分析社交媒体上的用户评论,以了解用户对网络性能的感知,并与用户行为进行比较;
- 使用User Signals as-a-Service(USaaS):
- 提出一个通用框架,将在线和离线的用户反馈相结合,以获取关于用户体验的有价值见解;
- 该服务可以帮助网络和网络服务提供商消费深入的用户体验洞察,从而改进网络性能和用户参与度。
Green With Envy: Unfair Congestion Control Algorithms Can Be More Energy Efficient
Serhat Arslan, Sundararajan Renganathan, Bruce Spang [Stanford University]
本文主要研究了拥塞控制算法对能源消耗的影响。研究者通过实验测量了不同拥塞控制算法在实验室环境下的能源消耗,并发现不同的算法行为对主机的能源消耗有显著影响。研究结果表明,增加最大传输单元(MTU)、减少流完成时间(FCT)和改变拥塞控制算法都可以降低能源消耗。此外,文章还探讨了网络设计和操作的其他方面对能源消耗的影响,并提出了未来进一步研究的方向。
为什么不公平的拥塞控制算法更节能?
- 边际能量使用随吞吐量的增加而减少:随着吞吐量的增加,总能量消耗增加,但端点的效率提高,这意味着每增加一个Gbps的吞吐量所需的能量减少。
- 快速完成流量传输:不公平的拥堵控制算法允许流量以线速率快速完成传输,然后进入空闲状态以减少能量消耗。相反,按照TCP公平分配的方式需要持续较高的能量消耗。
- 实验证明:实验证明,不公平的带宽分配是最节能的。“全速率,然后空闲”方法,即一个流量以线速率发送所有数据,另一个空闲,然后轮流发送,比公平分配的方法节省16%的能量。
不同拥塞控制算法是如何影响主机的能源消耗的?
- 分配带宽的公平性:实验结果表明,分配带宽的公平性可能会增加能源消耗高达16%。在一个实验中,当两个CUBIC流共享一个10 Gbps瓶颈链路时,使用最大速率发送数据的方法比公平分配带宽的方法更省电。
- 不同拥塞控制算法的能耗差异明显:使用不同的拥塞控制算法会导致能源消耗的显著差异。实验发现,在发送50 GB数据时,不同拥塞控制算法之间的能耗差异达到14%,这意味着在大规模应用中可能会产生显著的能源节约。
- 增加MTU(最大传输单元)可以节省能源:实验结果表明,增加MTU可以减少能源消耗。在一个实验中,将MTU从1500字节增加到9KB可以减少能源消耗13.4%至31.9%,这取决于所使用的拥塞控制算法。
- 减少流完成时间可以提高能源效率:实验证实,能源消耗与流完成时间密切相关。设计一个能够更快完成流传输的拥塞控制算法对于数据中心的环保和高性能需求至关重要。
如何通过改变最大传输单元(MTU)、减少流完成时间(FCT)和改变拥塞控制算法来降低能源消耗?
- 改变最大传输单元(MTU): 使用较大的MTU可以减少数据包处理的总开销,从而降低能源消耗。
- 减少流完成时间(FCT): 设计能够更快地完成流传输的拥塞控制算法,以降低能源消耗。
- 改变拥塞控制算法: 使用能源效率更高的拥塞控制算法。不同的拥塞控制算法可能导致不同的能源消耗,因此选择合适的算法对于降低能源消耗至关重要。
- 实现不公平的带宽分配: 研究表明,不公平的带宽分配可以提高能源效率。通过允许一些流更快地完成,从而让网络资源空闲并降低能源消耗。
Simplifying Cloud Management with Cloudless Computing
Yiming Qiu, Patrick Tser Jern Kon, Jiarong Xing†, Yibo Huang, Hongyi Liu† Xinyu Wang, Peng Huang, Mosharaf Chowdhury, Ang Chen [University of Michigan,Rice University]
本文的主要内容是介绍了一种名为"Cloudless Computing"的理念,旨在简化云计算基础设施的管理。作者认为目前的基础设施即代码(IaC)框架存在一些限制和不足,需要重新设计和完善。文章提出了几个关键问题,包括加速IaC部署、增量更新、以及基于策略的控制。作者认为通过解决这些问题,可以提高云基础设施管理的效率和可靠性。
Like serverless computing, which aims to reduce the burden of cloud users in managing server VMs, cloudless computing aims to support cloud infrastructure management on behalf of users by handling "cloudy" management tasks in a principled manner. This will reduce the friction in managing cloud-based infrastructures, so that developers and operators can work in a concerted fashion for better control over their infrastructure.
为什么目前的IaC框架存在部署速度较慢的问题?如何通过优化来加速IaC部署?
目前IaC框架部署速度较慢的问题主要原因有:
- 优化不足的规划和“最佳努力”的图遍历
- 资源依赖关系图分析未考虑特定于IaC的约束
- IaC部署过程中的错误处理和回滚机制不足
加速IaC部署的优化方法包括:
- 优化规划和图遍历,以加快部署速度
- 考虑特定于IaC的约束,以实现更高效的资源并行部署
- 改进错误处理和回滚机制,以减少部署过程中的时间损耗
- 实现增量更新,以加速云部署的变更
- 利用更强大的类型系统进行IaC验证,以捕捉潜在的部署问题及早解决
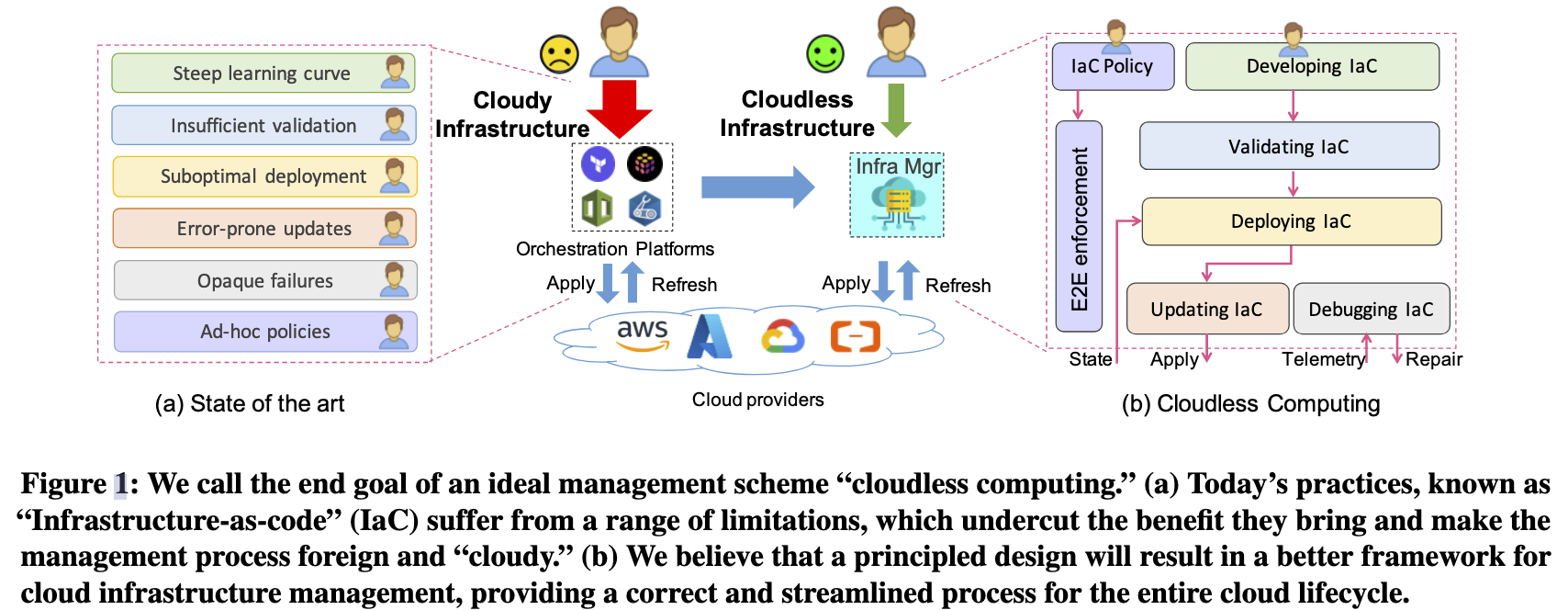
如何实现对云基础设施的增量更新,以减少对整个部署过程的重新计算和查询,从而提高更新效率?
- 使用结构化指导程序优化IaC程序:在开发阶段,可以使用程序优化器来提高IaC程序的结构质量,以便更容易地理解和维护。这可以通过分析和NLP-based方法从在线资源中自动提取资源类型和依赖关系图来实现。
- 减少资源状态查询和重新部署开销:通过识别部署更改的“影响范围”,可以将更改限制在一个显著较小的资源子图上。这将减少资源状态查询和重新部署的开销,从而节省成本。
- 实现更快的IaC部署:通过优化资源依赖图以找到并行部署的机会,可以加速IaC部署。有效的优化策略应考虑云API速率限制、各种云资源的估计部署时间、资源挂起或失败的重试等因素。
- IaC回滚期间的资源重新部署:在更新过程中,如果出现运行时错误或云用户自行要求回滚,可以识别那些不容易逆转的资源修改,然后使用新的部署从头开始破坏这些资源。这样可以减少回滚过程中的资源重新部署,并确保在执行任何更新之前可靠地识别回滚计划。
- 使用强大的IaC验证阶段捕获潜在部署问题:在验证阶段,可以引入更强大的IaC类型系统,以便在部署资源之前捕获潜在的部署问题。这将减少DevOps工程师在部署过程中花费的时间和精力。
- 实现IaC基础设施的批量锁定:在更新过程中,为了确保资源更新的隔离性,可以为每个资源提供锁定机制。这样,只有当相同资源被不同DevOps团队更新时,才需要相互排除。这将提供更精细的并行更新,同时保证隔离性。
作者提到了基于策略的控制,如何设计一个能够满足不同用户需求的策略控制器?如何更好地定义和实施用户特定的策略?
- 高级抽象:策略控制器应提供更高级别的抽象,以便用户更容易地编写策略。这意味着控制器应暴露用于执行策略的具有良好可见性的API。
- 支持自动策略生成:策略控制器应支持从现有IaC程序中自动推断出用户特定策略。这可以通过提取现有代码库中的模板来实现“异常检测”,从而比较新的IaC程序与现有模板之间的差异。
- 分离观察与动作:策略控制器应明确区分策略的观察和动作部分。这样,用户可以更好地定义所需的策略,同时控制器可以根据观察结果执行相应的动作。
- 灵活的策略语言:策略控制器应支持灵活的策略语言,以便用户可以定义各种不同的策略。这意味着语言应具有足够丰富的“观察”和“动作”,以便更好地支持用户定义的策略。
为了更好地定义和实施用户特定的策略,以下几点需要考虑:
- 明确策略规范:用户应明确定义其所需策略的规范,以便控制器可以根据这些规范执行相应的动作。
- 测试与验证:用户应测试和验证其定义的策略,以确保它们能够在实际场景中正常工作。这可以通过模拟不同场景并观察策略控制器的响应来实现。
- 持续优化:用户应定期评估其策略的性能并进行优化,以适应不断变化的需求和场景。这可以通过收集相关指标并分析策略执行的效果来实现。
Application Defined Networks
Xiangfeng Zhu1, Weixin Deng1, Banruo Liu2, Jingrong Chen3, Yongji Wu3, Thomas Anderson1, Arvind Krishnamurthy1, Ratul Mahajan1, Danyang Zhuo3 [University of Washington, Tsinghua University, Duke University]
本文主要介绍了应用定义网络(ADN)的概念,并围绕实现ADN提出了一系列关键的研究问题。文章讨论了高级规范如何在各种硬件和软件平台上进行高效的分布式实现,包括低级代码和数据包头设计;DSL应该提供什么样的抽象来指定RPC处理;以及如何确定网络处理发生的位置,并根据工作负载进行扩展/折叠,而不会影响应用程序。通过实现原型,作者展示了ADN可以显著降低端到端的RPC延迟,增加RPC吞吐量,并减少代码量。
ADN的核心思路是什么?包括哪些功能模块?每个功能模块分别承担怎样的功能?模块间如何交互?
ADN(Application Defined Networks)的核心思路是让应用程序定义其所需的网络行为,而不是依赖通用网络抽象。ADN包括以下功能模块:
- 编程抽象:使用类似SQL的语言为编译器提供描述RPC处理链的基础,同时支持其他所需功能。
- 控制平面:ADN控制器负责全局规划网络拓扑、服务位置和可用的ADN处理器,以便在可用资源上部署网络处理。
- 数据平面:ADN数据平面由ADN处理器组成,这些处理器在不同的硬件和软件平台上执行低级执行ADN元素。
模块间的交互:
- 编程抽象:开发人员使用DSL(领域特定语言)描述所需的网络功能。
- 控制平面:ADN编译器将DSL转换为高效的、分布式的实现,该实现跨越可用的硬件和软件资源。
- 数据平面:ADN处理器执行由控制平面分配的网络处理,并定期向控制器发送日志、跟踪和运行时统计信息。
ADN与服务网格相比有何优势,以及在哪些领域可以应用ADN的方法?
ADN(Application Defined Networks)与服务网格相比具有以下优势:
- 更高的性能:ADN通过定制化的网络实现,可以显著降低端到端的RPC延迟和提高RPC吞吐量。
- 更好的扩展性:ADN可以根据工作负载和故障动态重新配置网络,实现无缝扩展和收缩网络处理。
- 更高的定制化程度:ADN允许开发者完全定制应用网络,以满足特定应用程序及其部署环境的需求。
ADN方法可应用于以下领域:
- 微服务:ADN可以满足微服务之间的通信需求,如负载均衡、速率限制、身份验证、访问控制和测量。
- 数据分析:ADN可以支持分布式应用程序端点之间的定制通信功能,以提高数据分析的效率。
- 分布式机器学习训练:ADN可以用于分布式机器学习训练,以实现高性能和可扩展的网络处理。
Service meshes assume that applications emit IP packets that contain other standard protocols (e.g., TCP, HTTP, and gRPC). A local proxy intercepts these packets and, in the manner of middleboxes, parses and unwraps the network packets. It then applies the network policies and wraps the packets again before sending them to the receiver. The receiver has a local proxy as well, which also unwraps the packet, processes it, and wraps it again before handing it off to the application.
This architecture of service meshes has significant downsides. Depending on the configuration, it can increase message processing latency by up to 2.7-7.1x and CPU usage by up to 1.6-7x [ 3 , 9, 12, 52, 66]. Layering also hides or obscures information, which makes it hard to implement applicationspecific network policies (e.g., choosing replicas based on information in the application's RPC) [ 4 , 14]. Finally, being general, service mesh implementations are large and complex, so it is almost impossible to accelerate them via programmable kernel, NICs, and switches [28, 49, 50, 60].
Users are Closer than they Appear: Protecting User Location from WiFi APs [HotMobile'23]
Roshan Ayyalasomayajula, Aditya Arun, Wei Sun, and Dinesh Bharadia [UC San Diego]
本文主要介绍了一种名为MIRAGE的技术,旨在保护用户的位置信息免受WiFi接入点(AP)的侵犯。该技术通过使用波束成形和延迟等方法,使反射路径看起来像是直接路径,从而混淆攻击者对用户位置的观测。文章讨论了MIRAGE的实现和应用,并提出了一些未来的研究方向。
MIRAGE技术如何实现用户位置的混淆?具体的原理是什么?
MIRAGE技术通过以下方法实现用户位置的混淆:
- 通过波束成形和延迟来保留直接路径,从而保持通信吞吐量。
- 将直接路径延迟,使其在环境中的传播距离比反射路径更长,从而让攻击者无法确定用户的位置。(信号强度不受影响)
- 仅对直接路径添加延迟,使其在接收信号中无法与其他多径分离,从而保护用户位置。
具体原理如下:
- 在多径环境下,直接路径和反射路径之间存在一定的差异。MIRAGE利用这一特点,通过波束成形技术,在直接路径和多径之间进行权衡,使弱能量指向最强的多径,反之亦然。
- 在保留直接路径的同时,MIRAGE对直接路径添加延迟,使其在接收信号中被认为是多径。这样,攻击者无法确定用户的位置,即使他们知道MIRAGE已经改变了信道。
- 由于仅在直接路径上应用延迟,所以即使攻击者知道MIRAGE的实现,他们也无法恢复被延迟的直接路径,从而无法确定用户的位置。 因此,MIRAGE技术通过波束成形和延迟实现用户位置的混淆,同时保持通信链路的质量。
MIRAGE技术对网络吞吐量和通信延迟有何影响?如何平衡隐私保护和通信性能之间的关系?
MIRAGE技术对网络吞吐量和通信延迟的影响:
- 网络吞吐量:MIRAGE技术通过保留直接路径来保持信号的SNR,因此不会影响整体通信或数据速率。
- 通信延迟:MIRAGE通过在直接路径上添加延迟来混淆用户的位置。这种延迟对通信链路的影响微乎其微,因为仅在直接路径上添加延迟,而不影响反射路径。
平衡隐私保护和通信性能之间的关系:
- 使用MIRAGE技术时,可以选择适当的延迟来混淆用户的位置,同时保持网络吞吐量和通信延迟不受影响。
- 通过维持直接路径和保持信号的SNR,MIRAGE技术可以在保护用户隐私的同时确保通信质量。
- 当需要更高级别的隐私保护时,可以使用更长的延迟来混淆用户的位置,但这可能会导致通信延迟增加。在这种情况下,可以权衡隐私保护和通信性能之间的权重,以找到最佳平衡点。
TagAlong: Free, Wide-Area Data-Muling and Services [HotMobile'23]
Alex Bellon, Alex Yen, Alex Yen [UC San Diego]
我们演示了如何利用 Apple 的 Find My 协议,最著名的是 AirTag 的底层协议,用于任意数据记录和位置服务。这提供了一个新的“无基础设施”部署,其中具有频繁人类活动的区域可以利用这种零成本回程网络。虽然存在严重的限制(例如,没有确认通道回发送设备),但基于 My 的网络仍然可以是一个可靠的回程,具有足够的传输冗余和部署上下文的知识。为此,我们开发了 TagAlong,这是一种在 Find My 网络上可扩展、高效的数据传输协议。我们实现了一个概念验证,并展示了高达 12.5 字节/秒的吞吐量,高达 97% 的数据接收率。